注:文章又转载自我的公众号,所以图片水印是我公众号水印 #
 #
#
这是本人在4月29发的图,就不谋而合用了下面两位大神的方法,当然其实他们发布的时候都是5月份后了,而且我还用了厚涂法。当然了我的构图审美和下面两位大神没得比,而且我显卡出图实在太慢,很多细节最后都懒得改。ai绘图并不是随机抽卡,也顺便证明下为什么说ai已经取代绘图和摄影,但是没办法取代原画师和摄影师的原因。取代的只是流程,专业是无法取代的。
以下是转发两位大神的流程,未经允许,只会方便大家学习,如有侵权,告知即删除。 #
首先是顶级大神的天狗,原帖:Stable Diffusion + Matte Painting 全流程掌控|AIGARLIC|pixivFANBOX #
Stable Diffusion + Matte Painting 全流程掌控 #

By:Mazz
本教程是一个工作流详解,主要讲述如何在创作中,利用Stable Diffusion进行图像生成、图像融合、添加细节和放大的工作。
本教程适用人群:AI全流程掌控者。
#
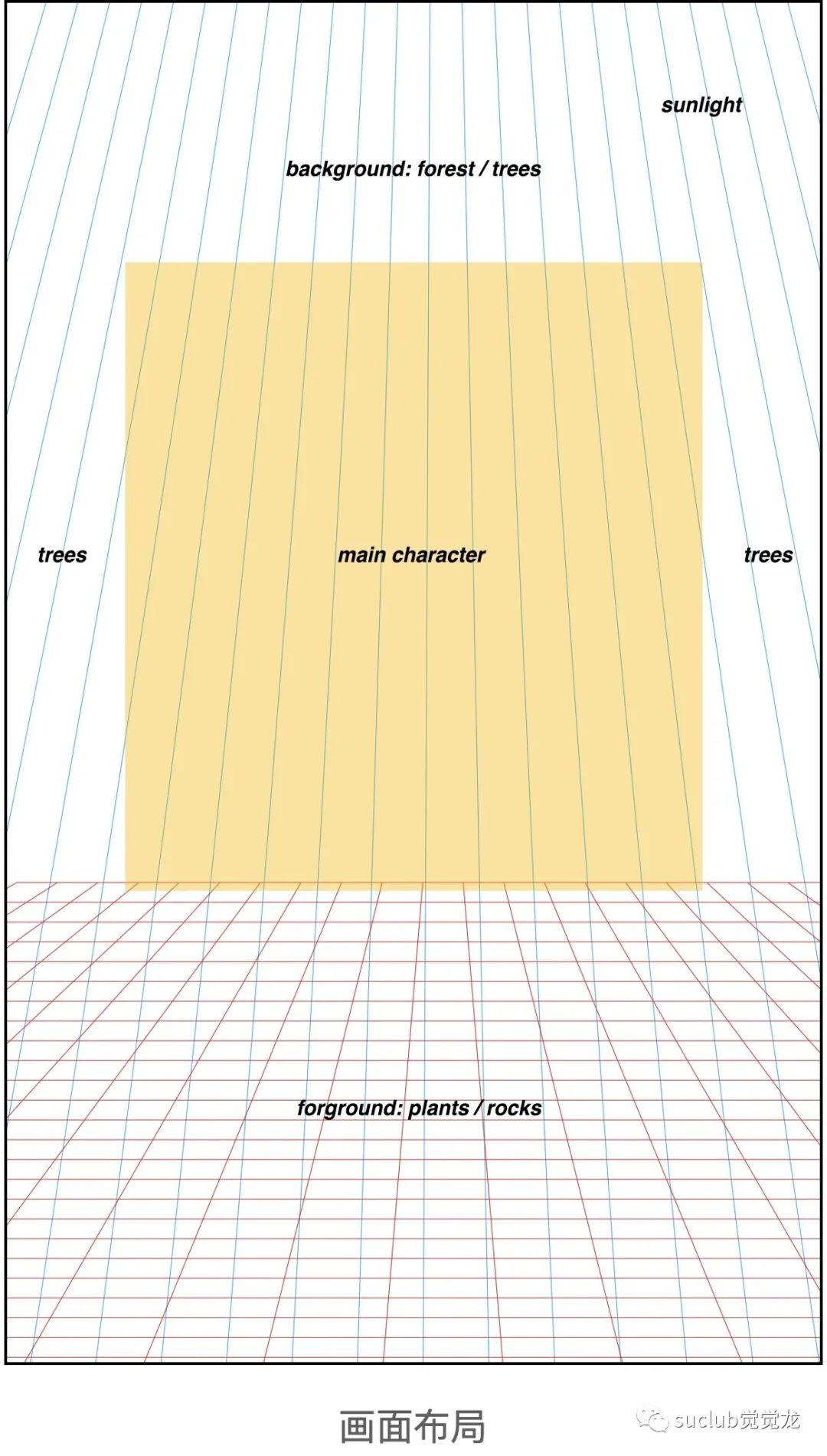
第一步:构思和构图 #
主题:描绘一个退休天狗隐居山林的形象
构图:采用竖构图,初始尺寸比例定为1152*1920px。
画面元素:背景为森林及阳光,中景为主要人物、石头和各种物品,前景为植物及土地
镜头:低视角,对焦中景,前景虚化。
第二步:背景绘制 #
找到森林和石头的图片素材,在Photoshop中进行合成,加入光线,粗略处理成想要的构图和透视角度。
使用Stable Diffusion img2img,生成最初的背景图
注意,此时不需要在意任何画面细节。生成的图片即使有一些错误也不需要修补。

#
第三步:人物绘制 #
首先需要确定人物动作。这里我在草图的基础上,用Clip Studio Pro中的3D人物模型进行姿态调整。你也可以使用其他3D Pose类软件生成人物姿态。
然后我们需要使用ControlNet的Openpose功能,生成人物姿态。
为了控制人物的色彩,可以用一张色彩合适的图片放入img2img中,将Denoising strength调至0.9以上,作为色板使用。当然,你也可以画出基本色稿放入img2img中,或是使用ControlNet Color等插件来控制色彩。
在此过程中需要进行img2img反复迭代,并且适时加入背景中的森林和光线元素,以便将来合成时人物与背景更易于融合。
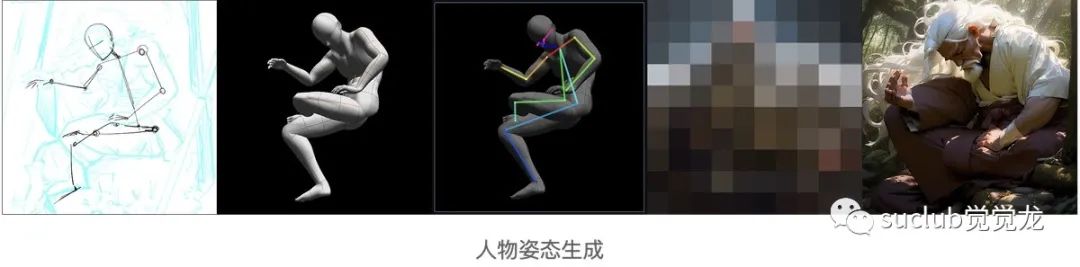
人物大致确定以后,使用photoshop进行简单融合,再使用img2img继续生成画面。此过程依然需要反复迭代,并配合inpainting和inpainting sketch进行调整。
至此,画面已经有了雏形。脸部角度和手都存在问题,但是不用急于修改。

Prompt: masterpiece, best quality, 1male, japanese monk, back lighting, ((rim light)), long hair, white hair, floating hair, white beard, long beard, meditation, in the forest with sunbeams shining through the trees, rocks laying on the ground in the foreground, depth of field, low angle
#
第四步:天狗 #
现在我们要让老人带上天狗面具。由于Stable Diffusion没有合适的模型和Lora可以方便地生成天狗面具,所以我为此训练了专用Lora。
Lora在使用时需要使用inpainting sketch进行重绘,或是使用Photoshop剪裁并简单手绘好面具后进入img2img重绘。注意重绘区域要小,以免Lora的风格污染画面的其他元素。
绘制Stable Diffusion不能很好地识别和绘制的特殊物品,最直接的方法就是自制Lora。

#
第五步:其他物品 #
延续之前的思路,在画面中一件一件添加其他物品。
方法仍然是:在画面局部使用Photoshop加入素材或使用Inpaiting Sketch绘制物体,再进行多次img2img迭代,得到满意的效果后,在Photoshop中进行融合,最后整体再使用img2img再次生成。
在绘制局部物体的时候,可以根据需要使用不同的模型和Lora,而不必担心整体画风发生改变。

#
#
第六步:局部修正 #
修正物体:包括手、物体比例等。
修正背景:由于AI无法理解物体的遮挡关系,所以背景中的树木会出现错位现象,我们需要手动修复树干被遮挡后的连续性。
此时,我们已经有了完整的画面,且画面中没有明显的瑕疵。

Prompt: masterpiece, best quality, 1male, japanese monk with a tengu mask and large beads necklace, a little puppy, a katana, a gourd, back lighting, ((rim light)), long hair, white hair, white beard, long beard, meditation, (textured clothing), ultra detailed, in the forest with sunbeams shining through the trees, rocks laying on the ground in the foreground, depth of field, low angle
#
第七步:放大 #
放大有几种方法:
使用Extra>Upscaler进行放大 - 无法增加细节
使用Ultimate SD upscale放大 - 对于元素较多的复杂画面容易出现错误
使用ControlNet Tile + Ultimate SD upscale放大 - 同样对于复杂画面容易出现错误
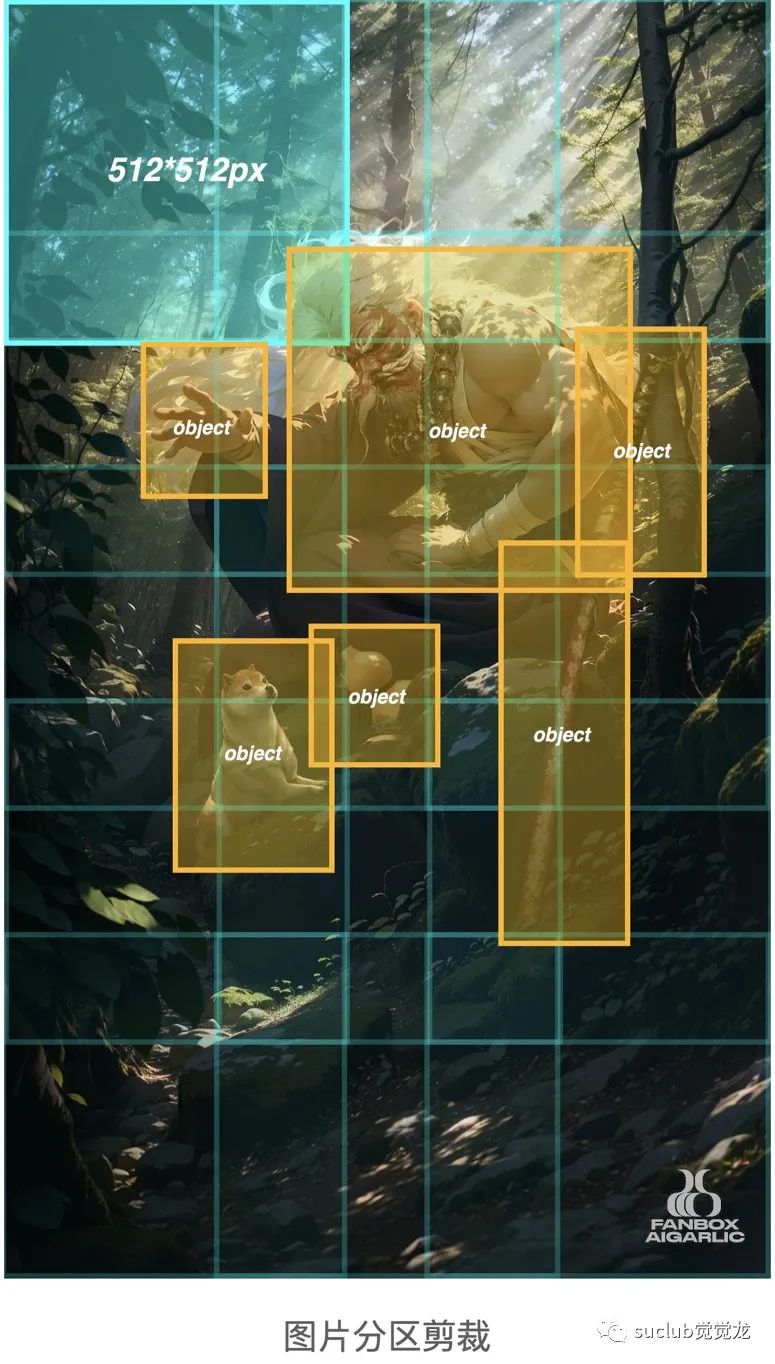
所以这一次我们需要使用手动分区放大。
用photoshop将画面均匀裁剪成512*512px的局部图
使用Stable Diffusion img2img逐一生成1920*1920px的图,
Denoising控制在0.39-0.49。
再针对重要的物体分别通过img2img进行放大生成,放大倍数为1920/512=3.75。
在分区域放大的过程中,可以使用ControlNet和Ultimate SD upscaler,增加更多细节。
#
最后,使用Photoshop将所有放大后的局部图进行拼合,精修,调色。 #
至此,所有工作就完成了!来看看最终效果。

结语 #
Stable Diffusion等AI绘图工具,目前还无法应对有元素丰富的复杂画面。特别是对画面有精确要求的时候,使用单一的img2img不能生成令人满意的效果。
本工作流的核心在于,每一个环节只让AI做一件事,提升AI对指令的精确理解。此外,这个工作流与传统绘画中“从整体到局部”的流程相似,对于习惯于手绘的画师比较友好。另外,由于90%的工作由作者本人把控,AI并没有过多的自由发挥,对作者而言,这体现了创作的本质。
附本工作流使用的模型和Lora:
Model: Lyriel V1.5 / DreamShaper V1.5
Lora: NijiExpressive V1.0 / MazzNohMask V0.5
其次是@blade2019runner 的天龙八部 #
1) Blender+OpenPose+PS #
首先,让我们看看这张图片。作者使用Blender创建了整个场景的白模,并利用ControlNet的线稿模式绘制出各个元素。接下来,他使用OpenPose来绘制人物的动作。完成这些步骤后,不断地进行局部重绘以改进画面效果。图中的文字是通过Photoshop在后期制作中加入的。




